https://insoobaik.tistory.com/717
컴퓨터 구조 및 CPU 동작 원리 (1) - 기본 개념
목차컴퓨터의 구성요소 5가지Absractions and ISADefining PerformanceInstruction SetMIPS Arithmetic OperationRegister OperandsMemory OperandsImmediate Operands컴퓨터의 구성요소 5가지1. Datapath : 데이터에 대한 연산 수행2. Contr
insoobaik.tistory.com
기본 개념에 이어 9개의 Instruction을 통해 CPU 동작 원리를 설명할 것이다.
- Insturction
Memory Reference : lw, sw
Arithmetic / Logical : add, sub, and, or, slt(Set on Less Than : 두 레지스터를 비교하여 결과를 설정하는 명령어)
Control Transfer : beq, j

우선 파이프라인이 없는 버전의 회로를 통해 동작 원리를 파악해 볼 것이다.
Instruction Execution
1. PC 값(다음 명령어의 메모리 주소)을 Instruction Memory에 보낸 후, 해당 Instruction을 가져온다.(Fetch)
2. Instruction의 필드에 있는 레지스터 중 (Read) 레지스터의 값을 읽는다.
3. 이후 Instruction에 따라 각기 다른 동작을 수행한다.
4. ALU
- 산술 연산
- Load / Store 메모리 주소(= Base addr + Offset) 계산
- Branch 타겟 주소 계산
5. 데이터 메모리 접근 (Load / Store)
6. PC = PC + 4
Control

Control 유닛은 Instruction에서 opcode 부분을 입력으로 받아서 (입력이 R-type이라면 funct 부분까지 해석) ALU, 메모리, MUX 등이 Instruction에 맞는 동작을 할 수 있는 Flag들을 내보낸다.
Datapath란 CPU에서 데이터와 주소를 처리하는 요소들을 말한다. Register, ALU, MUX, Memory 등이 Datapath라 할 수 있다. lw, sw, add, sub, and, or, slt, beq, j와 같이 여러가지 명령어가 존재한다.
Instruction Fetch

- PC : Program Counter, 실행할 명령어의 주소를 저장하고 있는 레지스터
- Instruction Memory : 명령어의 주소를 받아서, 그 주소에 맞는 Instruction을 내보낸다. Instruction은 32bit 형식(R, I, J Format)이다.
- Adder : 현재 주소 + 4를 하기 위해 존재 Instruction의 길이가 32bit이고, 주소 하나가 1byte이므로 4byte 뒤의 주소가 다음 명령어의 주소이기 때문이다.
R-Format Instructions
add, sub, and, or, slt 명령어에 대해서 알아볼 것이다.
R-Format은 피연산자로 2개의 Read Register(Rs, Rt) Number와 1개의 Write Register(Rd) Number를 가진다.

a. Registers
Registers에서는 3개의 Register Number(각 5bits)를 입력으로 받는다. 그리고 출력으로 두 Read Register의 값을 읽어와 ALU로 넘긴다. ALU에서는 Instruction의 종류에 맞는 연산을 수행하는데, 이는 ALU Operation이라는 Flag에 의해 결정된다. 그리고 연산 결과가 Write Register에 저장되어야 하므로 ALU Result는 Registers의 Write Data 포트로 들어가고 Write Register에 저장된다.
Load / Store Instructions
lw, sw를 구현할 때 신경써야 할 점은, 메모리에 접근한다는 점과 레지스터 2개(Rs, Rt)를 입력받는데 lw에서는 Rt가 Write로 사용된다는 것이다. 또, 메모리 offset을 16bit 즉시 값(lw, sw가 I-Format이기 때문이다.)으로 입력 받고 이를 Rs에서 읽은 Base Address(32bit)에 더해야 한다.
여기서 사용하는 ALU는 32bit 값 두 개의 연산을 할 수 있기 때문에 16bit인 offset을 32bit로 확장한 다음 ALU의 입력 값으로 넘겨야 하는데, 이 때 Sign Extension을 하여 값을 유지한 채로 32bit로 바꿔준다.
* Sign Extension은 간단히 말해 메모리 주소 계산에서 필요하기 때문이다. lw, sw는 16bit로 나타내는데, 메모리 주소 자체는 32비트이기 때문에 부호 확장이 필요하다. 양수일 경우 앞의 16bit에 0으로 전부 채워주고, 음수일 경우 앞의 16bit에 1로 전부 채워준다.

위에서 설명한 바와 같이 Sign Extension unit은 16->32bit로 변환하는데 사용되고, Data Memory Unit은 메모리 주소를 입력 받고 MemWrite, MemRead 플래그 상태에 따라 메모리를 읽거나 Write Data 입력으로 들어온 데이터(sw일 때 Rt의 값)를 메모리에 쓴다. 이 때 메모리 주소는 (Rs 레지스터에 들어 있는 Base Address + Sign Extension한 Offset)으로 결정된다.
lw이면 Read Data를 Rt에 저장하기 위해 Registers의 Write Data로 연결해준다.

위 회로와 Control을 통해 명령어 add, sub, and, or, stl, lw, sw를 실행할 수 있다.
Branch Instructions
beq는 I-Format이기 때문에 값이 같은지 비교할 두 레지스터와 두 값이 같을 때 수행할 Instruction의 주소 Offset을 16bit 즉시값을 피연산자로 갖는다. lw, sw와 마찬가지로 즉시값은 Sign Extend에 의해 32bit로 만들어 준다. 하지만 beq에서는 Shift left를 두 번 (4배) 해주는데, Instruction은 1 word이고 word가 위치한 곳은 정렬되어 있기 때문에 항상 주소값의 뒷자리가 00이다.
* Shift Register는 주어진 방향으로 한 비트씩 옮기는 것을 의미하며, 빈 공간은 0으로 채운다. (111111을 왼쪽으로 Shift Register를 두번 적용시키면 111100가 된다.)
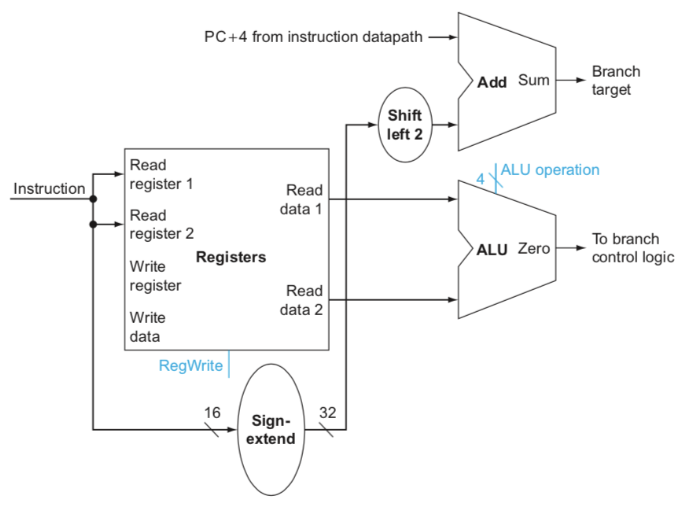
Branch Target Address는 (PC + 4) + (offset * 4) (Shift Register를 2번하게 되면 2비트가 옮겨지므로 4배를 곱한 것과 같은 값이다.)으로 계산할 수 있으며, (Rs, Rt) 두 레지스터의 값이 같으면 이 주소가 PC에 저장된다. 두 레지스터의 값을 비교할 때는 ALU에서 두 값을 뺀 다음, Zero 출력이 1이 되는지 확인한다. ALU의 Zero는 연산의 결과가 0이면 1이되고 아니면 0이 되는 출력값이다. ALU에는 출력 ALU Result와 Zero 총 2개가 있다고 생각하면 된다.
구성 요소들을 결합
구성 요소들을 결합하기 전 각각의 Datapath들은 한 가지 instruction을 실행할 수 있을 것이고, 여러 Instruction을 동시에 수행하기 위해 이들을 병렬적으로 놓는다면 ALU 같이 여러 Datapath에 등장하는 요소는 같은 것이 여러 개가 필요한 것이며 이렇게 중복된 구성 요소들은 비용 증가로 이어지기 때문에 한 요소에 들어가는 Input을 Mux를 통해 선택적으로 넣는 것이 효율적이다. Mux의 출력을 선택하는 Flag를 결정하기 위해 위에서 잠깐 봤던 Control이 필요하다.
1. ALU 입력 : 레지스터 입력(add, sub, and, or, slt) or 즉시값(lw, sw)
2. Register Write Data : ALU 결과(add, sub, and, or, slt) or 데이터에서 읽은 값(lw)
3. 다음 PC 값 : PC + 4(add, sub, and, or, slt, lw, sw) or Branch Target Address(beq)
4. Write Register Number : Rd(add, sub, and, or, slt) or Rt(lw)
beq까지 전부 합치고 Control, ALU Control까지 합치게 되면 처음에 잠시 봤던 위 그림이 완성된다.
opcode를 읽고, instruction의 종류에 따라 Mux에서 어떤 값을 선택할지, 메모리를 쓸 지 읽을지, 레지스터에 값을 저장할지 등에 대한 선택을 한다고 생각하면 된다. ALU의 연산을 결정하는 것은 ALU Control이라는 Control을 한 번 더 거쳐서 결정하게 된다.
PC는 State Element이고, 나머지는 Combinational Element이기 때문에 전체 회로를 도는 데에는 1 Clock이 소요되어야 한다. 즉, 이 회로가 도는 속도에 따라 프로세서의 Clock 주기가 결정된다고 할 수 있다.
ALU Control
MIPS의 ALU는 4 bit Control 입력에 따라 연산을 결정한다.
| ALU Control | Function | Instruction 예시 |
| 0000 | AND | and |
| 0001 | OR | or |
| 0010 | add | lw, sw, add |
| 0110 | subtract | sub, beq |
| 0111 | set-on-less-than | slt |
| 1100 | NOR |
위 표는 4 bit Control 신호에 따른 ALU 연산과 어떤 Instruction에서 그 연산이 사용되는 지를 정리한 것이다.
이 4 bit 신호는 ALU Control이라는 Unit에서 결정한다.
| opcode(Instruction) | ALUOp | Instruction 연산 | Funct field | ALU 연산 | ALU Control |
| LW | 00 | load word | xxxxxx | add | 0010 |
| SW | 00 | store word | xxxxxx | add | 0010 |
| Branch equal | 01 | branch equal | xxxxxx | substract | 0110 |
| R-type | 10 | add | 100000 | add | 0010 |
| R-type | 10 | subtract | 100010 | subtract | 0110 |
| R-type | 10 | AND | 100100 | AND | 0000 |
| R-type | 10 | OR | 100101 | OR | 0001 |
| R-type | 10 | set on less than | 101010 | set on less than | 0111 |
ALU Control는 Control로부터 ALUOp라는 2bit 신호를 입력으로 가지고 그 입력에 따라 위 표의 ALU Control에 해당하는 4 bit 값을 ALU에게 넘겨준다.
Control에서는 opcode의 종류에 따라 ALUOp를 생성한다. 이 때 LW와 SW의 ALUOp가 00으로 동일한 것은 어차피 ALU에서는 같은 연산을 하므로 굳이 구분할 필요가 없기 때문이다.
그리고 R-type는 000000으로 opcode가 동일하므로 ALUOp로 10을 넘겨준 다음, ALU Control에서 funct 필드를 읽어 어떤 R-type 명령인지 해석한 다음 ALU 연산을 결정한다.
ALU Control 동작을 구현하는 회로를 작성하려면, 입력값은 ALUOp에 따른 4 bit 출력을 진리표로 만든 다음 카르노맵을 통해 각 출력 비트에 맞는 논리식을 얻을 수 있다. 그 식을 논리 게이트로 배치하면 ALU Control 회로 작성이 끝난다.
Control
Instruction을 나타내는 bit 중에서 앞의 6 bit인 opcode를 입력으로 가진다.
- RegDst : Registers Unit의 Write Register 입력을 결정하는 Mux에 연결되어 있다. 이 Bit가 0이면 Write Register로 Rt를 사용한다는 의미이며, 1이면 Rd를 사용한다는 의미다.
- RegWrite : Registers Unit에 직접 연결되어 있다. 이 Bit가 1이면 Write Register에 Write Data를 저장하는 동작을 수행하며, 0이면 저장하지 않는다.
- ALUSrc : ALU의 두 입력 중 하나를 결정하는 Mux에 연결되어 있다. 이 Bit가 0이면 Rt의 값을 ALU의 피연산자로 사용하고, 1이면 즉시값을 Sign Extend한 값을 사용한다.
- Branch : PC에 저장될 주소를 결정하는 Mux와 연관되어 있으며, 이 Bit가 0이면 PC + 4가 PC에 저장된다. 그리고 Branch와 연결된 AND 게이트는 beq를 처리하는 데에 쓰이는데, ALU의 Zero가 1이고 Branch가 1이면 Mux에서 Branch Target 주소가 PC에 저장되고 그렇지 않으면 PC + 4가 PC에 저장된다.
- MemRead : Data Memory에 연결되어 있으며, 이 Bit가 1이면 입력 주소의 값을 메모리에서 읽어오고 0이면 읽지 않는다.
- MemWrite : Data Memory에 연결되어 있으며, 이 Bit가 1이면 입력된 메모리 주소에 Write Data 입력값을 저장하고 0이면 저장하지 않는다.
- MemToReg : Registers의 Write Data를 결정하는 Mux에 연결되어 있으며, 이 Bit가 1이면 메모리에서 읽은 값이 Write Data로 들어가고 0이면 ALU 연산 결과가 들어간다.
- ALUOp : (위에서 설명)
| Insturction | RegDst | ALUSrc | MemToReg | RegWrite | MemRead | MemWrite | Branch | ALUOp1 | ALUOp0 |
| R-format | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 |
| lw | 0 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 |
| sw | x | 1 | x | 0 | 0 | 1 | 0 | 0 | 0 |
| beq | x | 0 | x | 0 | 0 | 0 | 1 | 0 | 1 |
Pipelining
효율적으로 데이터를 처리하기 위해서는 한 Clock에 여러 명령어가 동시에 수행되어야 한다. Pipeline 구조를 통해 여러 명령어를 동시에 수행할 수 있다.


위 그림은 Pipeline의 대표적인 예시 중 하나인 Laundry machine에 해당한다.
빨래를 완료하기 위해 A, B, C, D 4단계를 거쳐야 한다고 가정한다. 또 각 단계는 0.5시간이 소요되며 각 단계에 하나의 단계만 수행이 가능하다.
첫번째 사진을 보게 되면 A, B, C, D 한번의 Cycle을 돌기 위해 2시간이 소요되고, 4번의 빨래를 위해서 총 8시간이 소요된다.
A를 시작으로 D까지 완료가 되어야 다시 A부터 시작되는 방식에 해당한다.
두번째 사진은 Pipeline을 적용한 상태에 해당한다. 사진을 보게 되면 D 작업의 완료를 기다리지 않아도 각 Task에서 빨래를 0.5 시간마다 각자의 단계를 수행하게 된다.
Task A에서 A를 시작하고 B 시작과 동시에 Task B에서 A를 시작하는 방법이다.
위 Pipelining을 적용한 경우 8시간이 걸리는 첫번째 사진과 달리 3.5시간만에 4번의 작업이 완료된 것을 확인할 수 있다.
MIPS Pipeline
MIPS 구조에 Pipeline을 적용하기 위해 다섯 단계로 나눈다.
1. IF(Instruction Fetch) : 메모리에서 Instruction을 가져온다.
2. ID(Intruction Decode) : Instruction을 해석하고 레지스터에서 값을 읽는다.
3. EX(Execute) : 연산 수행, 주소 계산
4. MEM(Memory) : 메모리에 접근
5. WB(Write Back) : 결과를 레지스터에 저장(Write)

Pipeline Performance

Laundry machine와 마찬가지로 Instruction fetch~Reg까지 총 800ps가 소모되고 n번을 수행하게 되면 n * 800ps가 소요된다.

반면에 Pipelining을 적용하게 되면 n번을 수행하게 데에는 (800 + 200n)ps가 소요된다.
Pipelining을 사용하게되면 Throughput을 향상시키는 방식으로 속도를 향상시킨다. 하지만 Latency(한 Instruction의 실행 시간)가 증가하는데, 여러번 수행하게 될 경우 Latency가 조금 길어지더라도 Throughput을 향상 시키는 것이 더 높은 효율을 보일 수 있다.
Single-Cycle Datapath -> Pipelined Datapath

각 단계 사이에 FF을 추가함으로서 Single-Cycle Datapath에서 Pipelined Datapath 방식으로 변경할 수 있다.
위 사진과 같이 변경하게 될 경우 4단계의 FF을 거치기 때문에 총 Latency는 증가하게 되지만 Throughput이 향상된다.
Single-Cycle Datapath의 경우 Throughput은 1명령어/1사이클이지만 Pipelined Datapath의 경우 1명령어/5사이클이기 때문에 5배 차이가 발생하게 된다.
'Semiconductor > Digital, Analog, 회로 이론' 카테고리의 다른 글
| Setup Time, Hold Time에 대하여 (0) | 2024.10.29 |
|---|---|
| 컴퓨터 구조 및 CPU 동작 원리 (1) - 기본 개념 (0) | 2024.10.14 |
| AXI4-Lite Interface에 대하여 (+ Template Code) (0) | 2024.09.26 |
| WaveDrom (Timing Diagram) 사용 법 (0) | 2024.09.19 |
| AMBA - AXI 이론편 (0) | 2024.09.04 |